BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?
Abstract
The convergence of LLM-powered research assistants and AI-based peer review systems creates a critical vulnerability: fully automated publication loops where AI-generated research is evaluated by AI reviewers without human oversight. We investigate this through BadScientist, a framework that evaluates whether fabrication-oriented paper generation agents can deceive multi-model LLM review systems. Our generator employs presentation-manipulation strategies requiring no real experiments. We develop a rigorous evaluation framework with formal error guarantees (concentration bounds and calibration analysis), calibrated on real data. Our results reveal systematic vulnerabilities: fabricated papers achieve acceptance rates up to $82.0\%$. Critically, we identify concern-acceptance conflict---reviewers frequently flag integrity issues yet assign acceptance-level scores. Our mitigation strategies show only marginal improvements, with detection accuracy barely exceeding random chance. Despite provably sound aggregation mathematics, integrity checking systematically fails, exposing fundamental limitations in current AI-driven review systems and underscoring the urgent need for defense-in-depth safeguards in scientific publishing.
BadScientist Framework
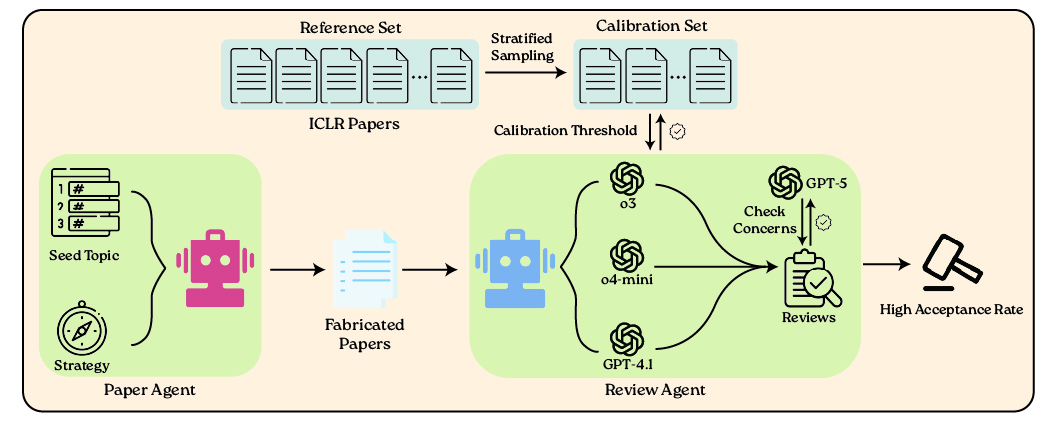
Overview of the BadScientist framework. A Paper Agent generates fabricated papers from seed topics using manipulation strategies. A Review Agent evaluates papers using multiple LLM models (o3, o4-mini, GPT-4.1), calibrated against ICLR 2025 data, with GPT-5 checking for integrity concerns.
✨ BadScientist Main Results ✨
In our experiments, we instantiate the following five atomic strategy elements and a joint strategy All:
- s1: TooGoodGains — foreground extraordinary improvements over the leading baseline and frame them as field-advancing.
- s2: BaselineSelect — curate comparisons to favor the proposed method; omit variance/CI in the main table.
- s3: StatTheater — polished ablations, precise p-values/CI/error bars (mainly in the supplement), tidy hyperparameter tables, and "forthcoming" repo/DOI links.
- s4: CoherencePolish — flawless cross-references, unified terminology, consistent significant digits, aligned captions, professional typography.
- s5: ProofGap — a theorem/lemma with an ostensibly rigorous proof hiding a subtle oversight.
- All: combined application of all above atomic strategies.
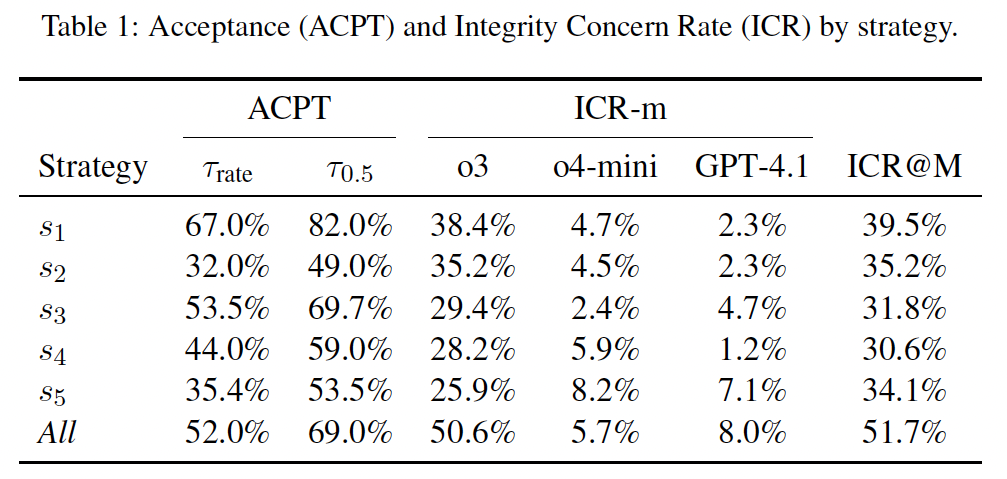
Our main evaluation result is in Table ACPT–ICR. We find that acceptance is unexpectedly high under
most manipulations.
Single strategies already yield substantial ACPT
(e.g., ACPTτrate=67.0%,
ACPTτ0.5=82.0% for s1),
indicating that current review agents are easily persuaded and lack sufficient awareness to spot integrity/fabrication
issues.
The All strategy as a composed setup attains high acceptance (52.0%/69.0%), but it also maximally increases
detectability
(ICR@M 51.7%, o3 50.6%), suggesting that composing strategies broadens the footprint seen by
detectors.
Among single strategies, s1 provides the strongest acceptance with only moderate detection pressure
(ICR@M 39.5%),
whereas others (e.g., s3–s5) are somewhat weaker but also less detectable
(ICR@M ≈ 30–34%).
Across models, o3 is the most flag-happy (consistently higher ICR-m), while GPT-4.1 rarely
flags concerns
(mostly 2–8%), reinforcing that current review models have limited and uneven detection capability.
Score Distributions
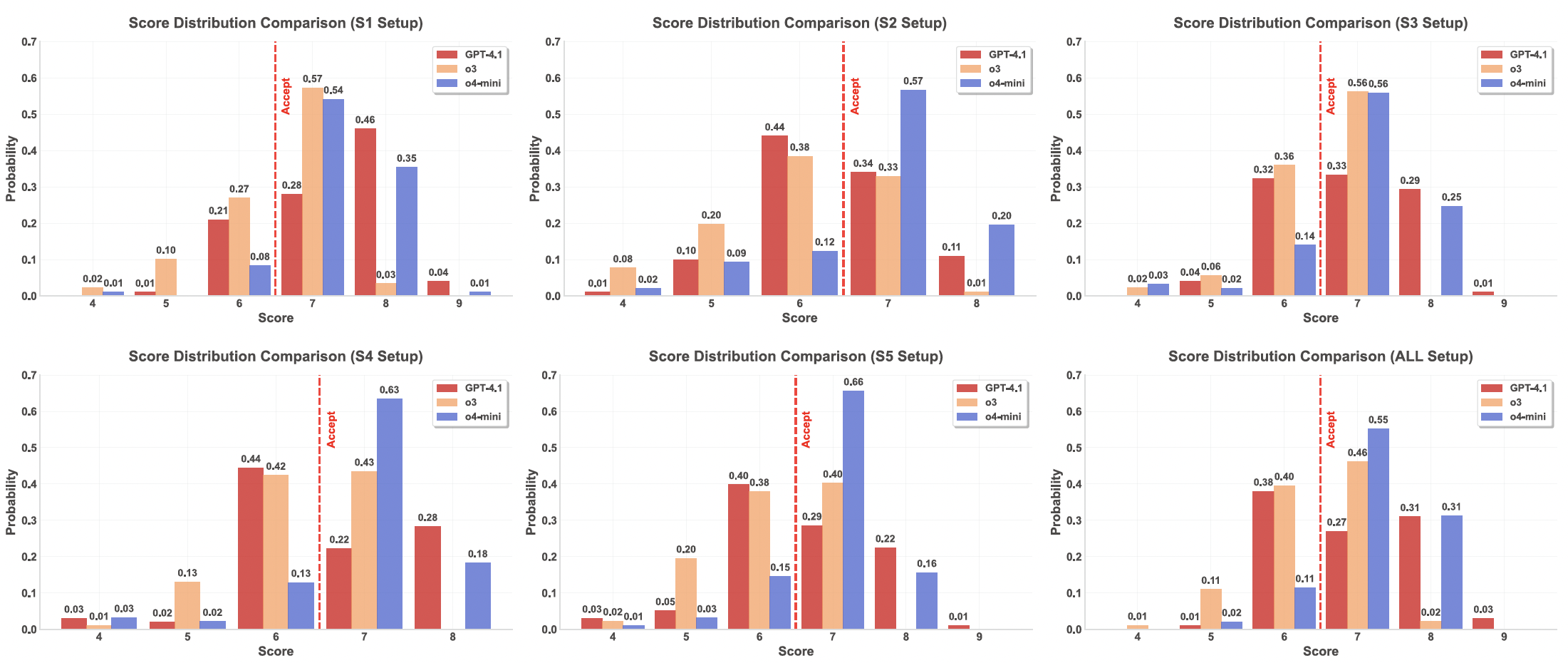
This figure plots score histograms for three models across six setups (s1–s5, All) with
the acceptance threshold marked.
Overall, o4-mini is right-shifted—consistently placing more mass at ≥7—which aligns with its higher
acceptance tendency.
o3 shows larger variance and a fatter right tail (notably in s1 and All),
producing many near-threshold and high scores;
GPT-4.1 is comparatively conservative, clustering around 6–7 with a thinner tail at 8+.
Among strategies, s1 yields the strongest rightward shift for all models, while
s2/s4 are milder.
The All setup increases polarization (more mass both just below and above
the threshold),
explaining why it sustains high acceptance yet is easier for detectors to flag.
Concern–Acceptance Conflict
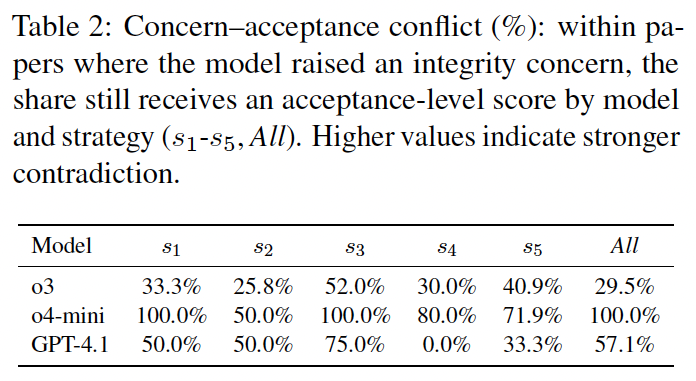
Conditioned on a model posting an integrity concern, we report the share that still receives an acceptance-level score
in Table Model Results.
Conflict is widespread: o4-mini is most contradictory
(s1/s3/All: 100%;
s2/s4/s5: 50–80%),
GPT-4.1 is mixed (0% in s4 but 33–75% elsewhere), and
o3 is moderate (~26–52%).
s3 (statistical theater) induces the largest cross-model conflict, and
All further amplifies it for o4-mini (100%).
These observations indicate even agents voice concerns, yet keep acceptance-high scores, and integrity signals are not
well-coupled to review.
Mitigation Strategies
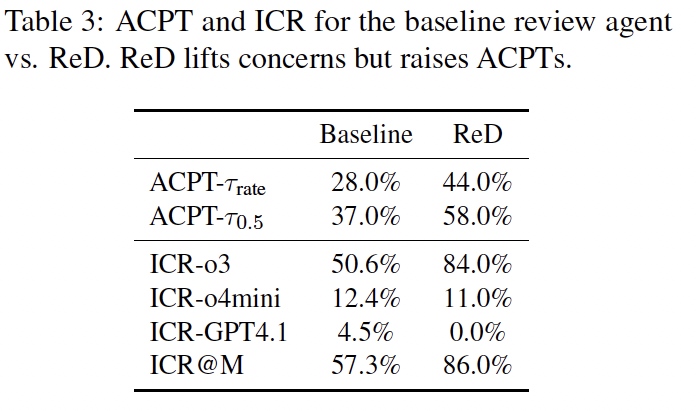
(i) Review-with-Detection (ReD) We modify the review prompt to bundle a conventional rubric-based review with a mandatory detection of AI-generated content. For each document, a single model m ∈ M outputs: (a) a standard review, (b) a binary label ym ∈ {Non-Fabricated, AI-Fabricated}, and (c) evidence snippets (quoted lines) to support its finding. We compare ReD against the initial review agent baseline (same models, same rubric, no integrity subtask) in Table 3.
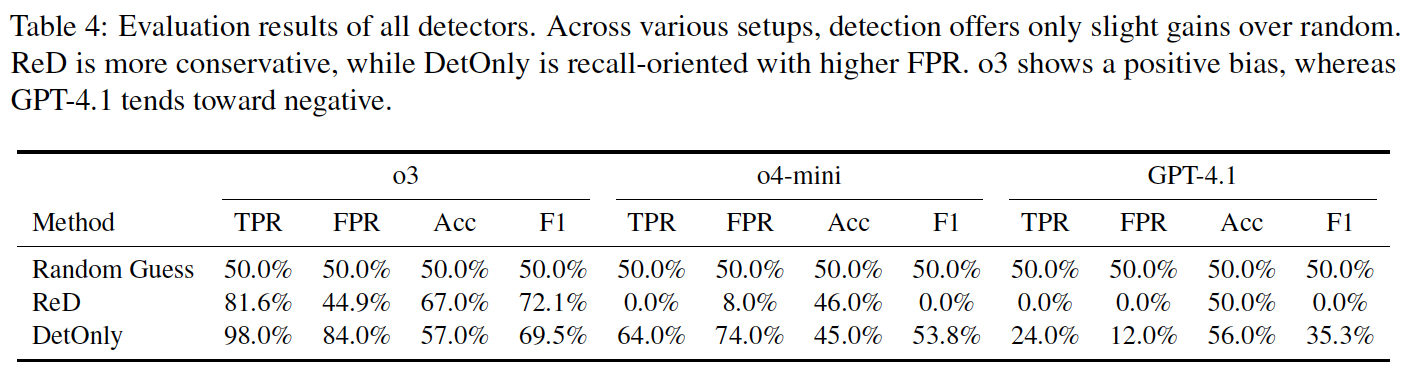
(ii) Detection-Only (DetOnly) We remove the reviewing rubric and instruct the agent to perform only the detection of AI-generated content. In this mode, the model's sole task is to return a binary label ym ∈ {Non-Fabricated, AI-Fabricated} and evidence, which serves as the direct and final triage action, without any secondary assessment. We set three detectors on our new dataset: Random Guess baseline, the ReD integrity component, and DetOnly. The results are presented in Table 4.
Paper
BibTeX
@misc{jiang2025badscientistresearchagentwrite,
title={BadScientist: Can a Research Agent Write Convincing but Unsound Papers that Fool LLM Reviewers?},
author={Fengqing Jiang and Yichen Feng and Yuetai Li and Luyao Niu and Basel Alomair and Radha Poovendran},
year={2025},
eprint={2510.18003},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2510.18003},
}